
LLaMA 2: Open Foundation and Fine-Tuned Chat Models
Abstract: In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closedsource models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
What we gonna do: LLaMA 2: Key Improvements and Insights over LLaMA 1
\[\text{LLaMA 2} = \text{LLaMA 1} + \text{GQA} + 2T \text{ tokens} + \text{SFT}_{human} + \text{RLHF}_{dual RM} + \text{GAtt}\]1. Model Architecture (from Section 2.2)
1.1 Grouped Query Attention (GQA)
LLaMA 2 introduces Grouped Query Attention (GQA) to improve inference efficiency, especially in large models like LLaMA 2–34B and 70B.
Unlike standard Multi-Head Attention (MHA), GQA reduces the number of key/value heads while retaining multiple query heads, offering a trade-off between Multi-Query Attention (MQA) and MHA.
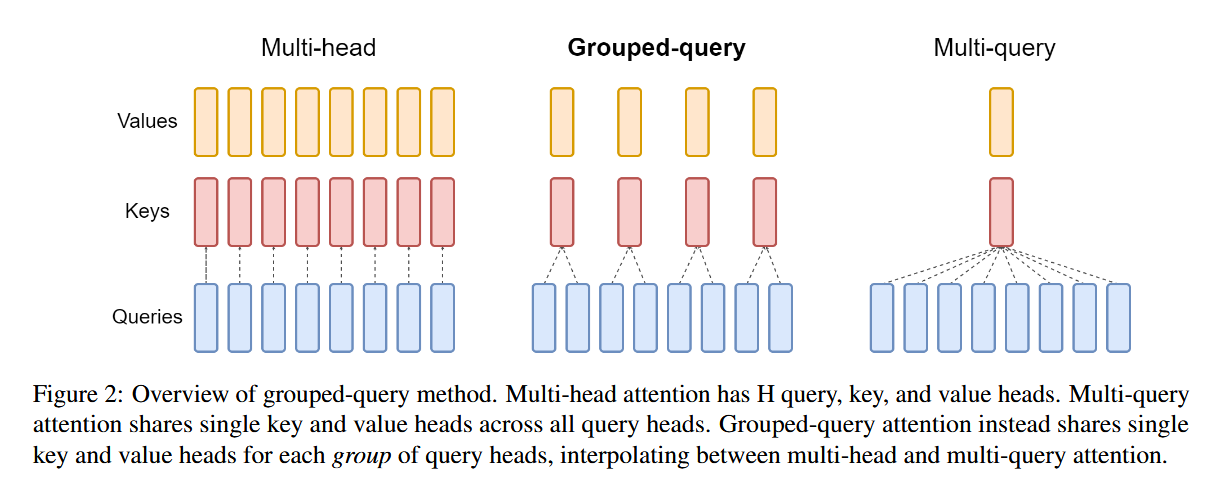
1.1.1 What’s the Problem of Multi-Head Attention (MHA)
In standard multi-head attention, each head has its own query, key, and value:
- $H$ query heads
- $H$ key heads
- $H$ value heads
This leads to:
- Large memory usage during inference due to storing all key and value vectors in the KV cache
- Slower inference, especially in decoder-only models with long context lengths
The attention score computation per head is:
\[\text{Attention}(Q_h, K_h, V_h) = \text{softmax}\left(\frac{Q_h K_h^\top}{\sqrt{d_k}}\right) V_h\]1.1.2 Prior Solution: Multi-Query Attention (MQA)
MQA simplifies this by:
- Using $H$ query heads
- Sharing one key and one value head across all query heads
This significantly reduces KV cache size and improves inference speed:
- From $H$ KV caches $\rightarrow$ only 1 KV pair
However:
- It often degrades model quality
- Reduces diversity of attention
- Unstable in certain tasks like long-form generation and reasoning
1.1.3 GQA: A Middle Ground
Grouped Query Attention (GQA) interpolates between MHA and MQA:
- Divide the $H$ query heads into $G$ groups
- Each group shares one key and one value head
This gives:
- $H$ query heads
- $G$ key heads
- $G$ value heads
Special cases:
- $G = 1$ → equivalent to MQA
- $G = H$ → equivalent to MHA
GQA allows flexible configuration:
\[\text{GQA-}G: \quad \text{each group of } \frac{H}{G} \text{ queries shares a KV pair}\]1.1.4 GQA in KV Cache and Implementation Details
GQA significantly reduces KV cache memory:
- From $H$ sets → $G$ sets
- Reduces memory and bandwidth requirements in decoding
def mha(x, c_attn, c_proj, n_head, kvcache=None): # [n_seq, n_embd] -> [n_seq, n_embd]
# qkv projection
# when we pass kvcache, n_seq = 1. so we will compute new_q, new_k and new_v
x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# split into qkv
qkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> [3, n_seq, n_embd]
if kvcache:
# qkv
new_q, new_k, new_v = qkv # new_q, new_k, new_v = [1, n_embd]
old_k, old_v = kvcache
k = np.vstack([old_k, new_k]) # k = [n_seq, n_embd], where n_seq = prev_n_seq + 1
v = np.vstack([old_v, new_v]) # v = [n_seq, n_embd], where n_seq = prev_n_seq + 1
qkv = [new_q, k, v]
In LLaMA 2:
- GQA is used in the 34B and 70B models
- Value of $G$ (number of KV groups) is a hyperparameter (e.g., 8 or 16)
Training insights (from the GQA paper):
- Existing multi-head checkpoints can be converted to GQA
- Simple method: mean-pool the key/value heads within each group
- Only 5% of training steps needed to re-adapt after conversion
1.1.5 Benefits
| Property | Multi-Head Attention (MHA) | GQA | Multi-Query Attention (MQA) |
|---|---|---|---|
| Query heads | $H$ | $H$ | $H$ |
| Key/value heads | $H$ | $G$ | $1$ |
| KV Cache Size | High | Medium | Low |
| Inference Speed | Slow | Faster | Fastest |
| Model Quality | ✅ Best | ✅ Close to MHA | ❌ Often Degrades |
| Flexibility | ❌ No | ✅ Tunable ($G$) | ❌ Fixed |
GQA provides an ideal trade-off between efficiency and expressiveness for large autoregressive models, especially useful in high-throughput decoding like in LLaMA 2–Chat.
1.2 Context Length Extension
LLaMA 2 extends the context length from 2048 to 4096 tokens. This is achieved not by retraining with longer sequences from scratch, but by applying a technique called position interpolation.
1.2.1 The Problem
Rotary Position Embedding (RoPE) encodes position-dependent rotations for queries and keys using:
\[\theta_i^{(k)} = \frac{i}{10000^{2k/d}}\]Where:
- $i$ is the position index
- $d$ is the embedding dimension
- $k$ indexes dimension pairs
RoPE is trained with a maximum context length $L_{\text{train}}$ (e.g., 2048). Using it at longer lengths like 4096 results in extrapolation, which degrades performance due to unseen frequency phases and instability in long-range attention.
1.2.2 The Solution: Position Interpolation
Instead of extrapolating, LLaMA 2 uses position interpolation (Chen et al., 2023). During inference, the input position $i$ is rescaled to a compressed position $\tilde{i}$:
\[\tilde{i} = i \cdot \frac{L_{\text{train}}}{L_{\text{target}}}\]Where:
- $L_{\text{train}}$ is the max position used during training (e.g., 2048)
- $L_{\text{target}}$ is the desired context length during inference (e.g., 4096)
This ensures:
\[\theta_i^{(k)} \longrightarrow \theta_{\tilde{i}}^{(k)} = \frac{i \cdot L_{\text{train}}}{L_{\text{target}} \cdot 10000^{2k/d}}\]So instead of feeding position $i$ directly into RoPE, a scaled version $\tilde{i}$ is used to compress the effective position range into what the model has seen during training.
1.2.3 Benefits
- Allows inference at 4096 tokens despite training with 2048
- Avoids retraining the positional encoder
- Maintains stability of relative attention
- Zero additional cost during inference
Position interpolation enables LLaMA 2 to generalize to long sequences without architectural change or retraining, and is critical for making the 4k context extension viable.
1.3 Retained Features from LLaMA 1
- Rotary Positional Embedding (RoPE)
- SwiGLU activation
- RMSNorm and pre-norm architecture
2. Pretraining (from Section 2.1 and 2.2)
2.1 Dataset and Scale
LLaMA 2 significantly improves on LLaMA 1 by expanding and refining its pretraining dataset. This follows the Chinchilla scaling principle: train on more tokens for better compute efficiency and model quality.
- 2T tokens vs 1.0–1.4T in LLaMA 1
- Cleaner, higher-quality data sources
- Public + curated proprietary datasets
2.1.1 Scale
LLaMA 1 was trained on approximately 1.0–1.4 trillion tokens.
LLaMA 2 increases this to:
- 2 trillion tokens for all model sizes (7B, 13B, 34B, 70B)
- A ~40% increase in training data compared to LLaMA 1
This aligns with Chinchilla scaling laws that suggest better results from smaller models trained on more data, rather than scaling parameters alone.
2.1.2 Data Composition
LLaMA 2 continues to rely on publicly available and curated sources, but with improved filtering and diversification.
Though precise dataset compositions are not disclosed, the authors report:
- Greater emphasis on high-quality web data, code, and scientific content
- Inclusion of multilingual data
- Improved deduplication, document-level filtering, and text quality scoring
Compared to LLaMA 1, the dataset has:
- Fewer noisy or duplicated sources
- Better semantic diversity and factuality
2.1.3 Data Quality Focus
To ensure high downstream performance and safety, LLaMA 2 uses:
- Contamination filtering against popular benchmarks
- Reduced overlap with evaluation datasets like MMLU, TruthfulQA, etc.
- Alignment with safety and harmlessness standards
These improvements are particularly critical for the later stages of supervised fine-tuning and RLHF.
2.1.4 Data for LLaMA 2-Chat
The base LLaMA 2 models are used as the foundation for instruction-tuned LLaMA 2-Chat.
Additional data for chat models includes:
- Human-written prompt-response pairs
- Safety-sensitive instruction scenarios
- Dialogue-oriented and multi-turn formats
This data is not part of the 2T pretraining corpus but is used later in SFT and RLHF stages.
LLaMA 2’s improved dataset scale and quality allow it to train models with stronger generalization, factual reasoning, and instruction-following performance than its predecessor.
2.2 Training Infrastructure and Strategy
- Trained on Meta’s in-house clusters (A100 GPUs)
- Optimized batch size, learning rate schedule
- No dropout, longer training steps
3 Supervised Fine-Tuning (SFT)
LLaMA 2 follows the standard two-stage instruction tuning pipeline, where a pretrained base model is first adapted using high-quality supervised instruction-following data. While the architecture and method are unchanged, LLaMA 2 significantly improves the data quality, format enforcement, and safety scope of SFT.
3.1 High-Quality Instruction Dataset
- All prompt-response pairs are human-written, not generated by large models.
- Data is collected across a wide range of domains:
- Reasoning and logic
- Dialogue and task completion
- Summarization, classification, translation
- Coding and math queries
- Tasks are framed in naturalistic and open-ended ways, to better reflect real usage.
This high-quality dataset is the base on which RLHF is later applied.
3.2 Format Enforcement
To improve output structure and ensure formatting consistency, the SFT dataset includes:
- Explicit roles: e.g., User, Assistant
- Markdown usage: bullet points, numbered lists, code blocks
- Instruction patterns: task descriptions followed by expected behavior
- Multi-turn prompts with maintained structure across turns
This design helps with:
- Better zero-shot generalization in formatting
- Compatibility with chat UIs and downstream tool pipelines
3.3 Safety-Conscious Prompts
The SFT phase includes explicitly adversarial and sensitive prompts, covering topics like:
- Hate speech, bias, misinformation
- Self-harm, illegal activity, political manipulation
- Provocative or ambiguous edge cases
These prompts are not filtered out — they are included to:
- Provide early exposure to unsafe instruction types
- Enable RLHF to more effectively fine-tune harmlessness
While the SFT model is not fully safe on its own, this design makes it a better candidate for the next RLHF stage.
LLaMA 2’s SFT stage is not algorithmically new, but its data improvements are critical for enabling strong instruction-following, safe behavior, and downstream fine-tuning efficiency.
4. Reinforcement Learning with Human Feedback (RLHF) (Section 3.2 and 3.4)
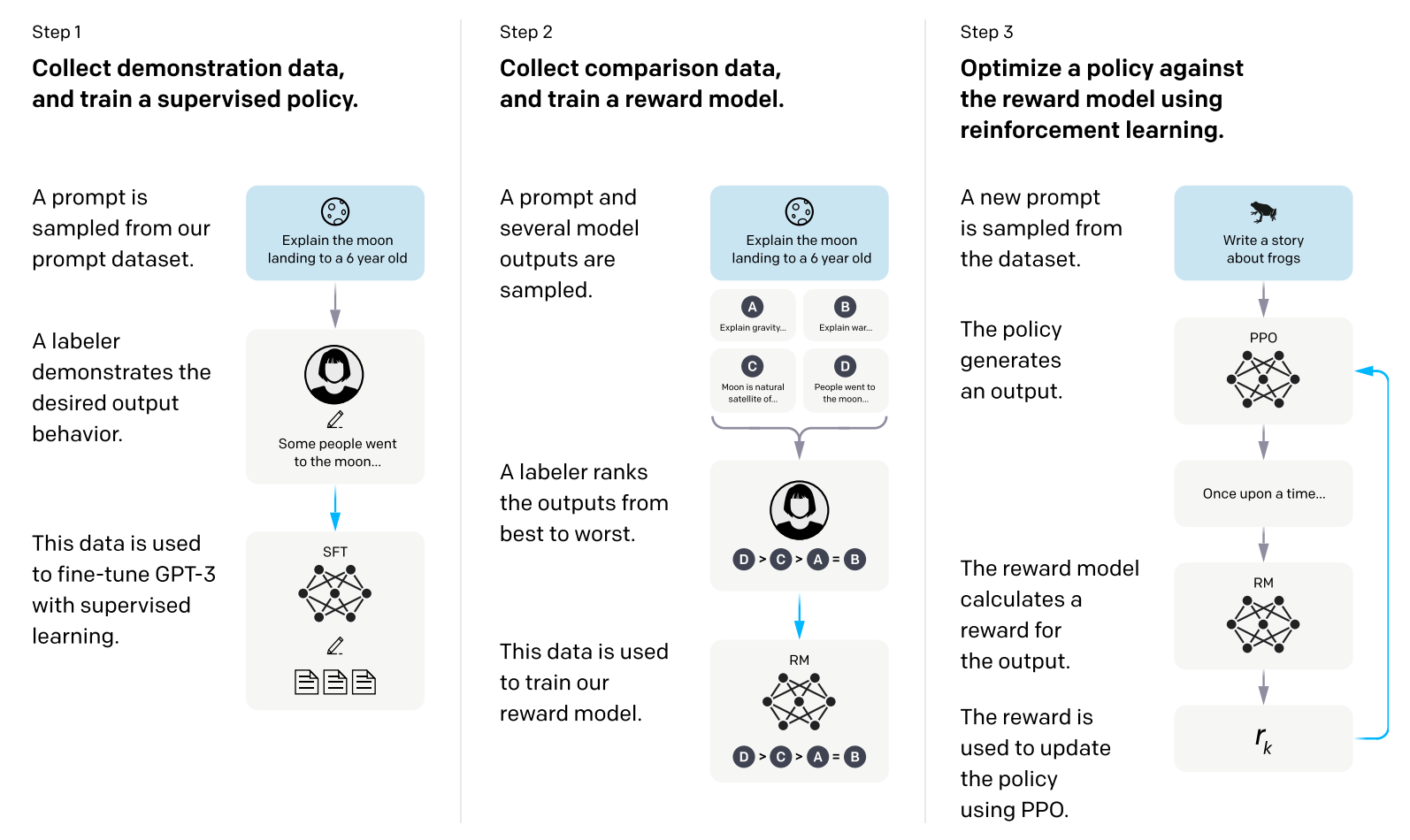
This picture is from paper: Training language models to follow instructions with human feedback
4.1 Reward Modeling
Reward modeling is a core component of Reinforcement Learning with Human Feedback (RLHF). In LLaMA 2, reward models (RMs) are used to score model outputs based on human preferences — enabling the model to learn alignment objectives like helpfulness and safety.
Two separate reward models:
- Helpfulness
- Safety
Trained using pairwise preference data.
4.1.1 What Is a Reward Model (Compared with a Reward Function)
- A reward function in classical RL is hand-crafted and deterministic, e.g., $r(s, a)$.
- A reward model, by contrast, is a learned function trained from human preference data.
In language models:
- The model generates two candidate responses $y_1$, $y_2$ for the same prompt $x$.
- A human annotator picks the better one.
- The reward model is trained to assign higher reward to the preferred sample:
- The loss is typically pairwise preference loss:
Where $\sigma$ is the sigmoid function.
The reward model thus learns to approximate human judgment, and its output is used in PPO or rejection sampling.
4.1.2 How Does LLaMA 2 Construct the Reward Model
LLaMA 2 uses two separate reward models:
- One for Helpfulness
- One for Safety
These are trained independently, each on pairwise preference datasets annotated by humans.
Data:
- Prompt-response pairs with human rankings
- Includes a wide variety of domains and safety-critical scenarios
Model Architecture:
- The reward model shares the same backbone as LLaMA 2 (e.g., 7B/13B)
- Adds a linear head on top of the final hidden state to produce a scalar reward
Training Objective:
- Pairwise ranking loss as above
- Optionally applies regularization to prevent reward hacking
To train the reward model, we convert our collected pairwise human preference data into a binary ranking label format (i.e., chosen & rejected) and enforce the chosen response to have a higher score than its counterpart. We used a binary ranking loss consistent with Ouyang et al.
The loss can be wrote as:
\[\mathcal{L}_{\text{ranking}} = -\log \sigma\left( r_{\theta}(x, y_{\text{chosen}}) - r_{\theta}(x, y_{\text{rejected}}) \right)\]where $R(x, y)$ is the reward model score for the response $y$ given the prompt $x$, and $\theta$ are the model weights.
Use in RLHF:
- During PPO, the language model generates outputs
- Reward is computed as:
- This signal is used to update the policy (LLaMA 2-Chat) to maximize helpfulness while minimizing unsafe behavior
LLaMA 2’s reward modeling stage is critical for building the alignment signal used in RLHF, and the use of dual reward models (for helpfulness and safety) is a key innovation over single-RM setups like in InstructGPT.
4.2 Fine-Tuning with PPO
After supervised fine-tuning and reward model training, LLaMA 2 uses Proximal Policy Optimization (PPO) to fine-tune the model’s behavior based on human preferences. PPO allows the model to learn from scalar reward signals generated by the reward models, adjusting its output distribution to be more aligned with helpful and safe responses.
- Proximal Policy Optimization for stable training
- Uses reward signal from both models
4.2.1 What Is PPO?
Proximal Policy Optimization (PPO) is a policy gradient method from reinforcement learning. It is designed to:
- Stabilize training by constraining updates
- Avoid drastic changes to the model’s behavior
The PPO objective function is:
\[\mathcal{L}_{\text{PPO}} = \mathbb{E}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \; \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t \right) \right]\]Where:
- $r_t(\theta) = \frac{\pi_\theta(a_t \mid s_t)}{\pi_{\text{old}}(a_t \mid s_t)}$ is the ratio of new to old policy
- $\hat{A}_t$ is the advantage estimate
- $\epsilon$ is a clipping parameter
This formulation ensures the policy doesn’t deviate too far from its original distribution — crucial for language models that may otherwise produce degenerate outputs.
4.2.2 PPO in LLaMA 2
In the LLaMA 2 RLHF pipeline:
- The SFT model serves as the initial policy
- The reward model computes scalar rewards for generated outputs
- PPO is applied to maximize the expected reward
During optimization:
- Each training sample includes a prompt and generated response
- Rewards are calculated using the dual RM setup:
- The policy is updated to maximize this reward while remaining close to the original SFT distribution
4.2.3 Regularization and Stability
To maintain stable training, LLaMA 2 uses:
- KL penalty between the new and old policy
- Clipping as in standard PPO to limit policy shifts
- Early stopping and tuning of batch sizes and rollout lengths
This ensures that:
- The model improves in alignment
- It avoids reward hacking or distributional drift
- It preserves linguistic fluency and factual correctness
LLaMA 2 uses PPO to align model behavior with human preferences, balancing helpfulness and safety via the dual reward model setup, and maintaining output stability through policy regularization.
4.3 Rejection Sampling
Rejection Sampling is an auxiliary method used alongside PPO to further align the model’s responses with human preferences. It does not require gradients or backpropagation — instead, it selects the best response from a set of candidates using the reward model.
- Sample multiple responses per prompt
- Retain only the highest-ranked according to RM
- Improves controllability without destabilizing policy
4.3.1 Motivation
Even after PPO, there may be variance in the quality of generated outputs. By sampling multiple candidate responses and filtering based on reward scores, we can:
- Increase the quality of the final output
- Enforce stricter adherence to the reward model
- Improve controllability without needing further training
This also mitigates instability or reward hacking that can emerge during PPO updates.
4.3.2 Method
Given a prompt $x$:
- Generate $k$ candidate completions: $y_1, y_2, \dots, y_k$
- Evaluate each using the trained reward model:
- Select the highest-scoring response:
The chosen output $y^*$ is returned to the user (or used as training data in bootstrapped pipelines).
4.3.3 Use in LLaMA 2
- Used during model evaluation and sometimes during finetuning rollout phases
- Often applied after PPO, not as a replacement
- Helps enforce strict safety constraints via rejection of unsafe generations
4.3.4 Trade-Offs
| Pros | Cons |
|---|---|
| Improves output quality | Requires multiple forward passes |
| Reduces reward hacking effects | Inference cost increases |
| Tightens alignment with human intent | No learning signal, selection only |
Rejection sampling in LLaMA 2 acts as a low-cost, post-hoc filter that ensures high-quality and aligned generations, especially useful when safety and response precision are critical.
4.4 RLHF Evaluation
- Tested on Anthropic HH, TruthfulQA, MT Bench
- Better balance between helpfulness and harmlessness
5. System Message and Multi-Turn Consistency (Section 3.3)
5.1 Ghost Attention (GAtt)
- System instruction (e.g., “you are a helpful AI”) is attended to but not generated
- Helps maintain consistent behavior over multiple turns
5.2 Multi-Turn Chat Stability
- Critical for LLaMA 2-Chat’s usability
- Outperforms LLaMA 1-style instruction tuning
6. Safety Pipeline (Section 4)
6.1 Safety in Pretraining
- Careful curation to avoid toxic or biased pretraining data
6.2 Safety during Fine-Tuning
- Combined with reward modeling
- Includes manual annotation for unsafe behavior
6.3 Red Teaming
- Manual and adversarial testing with expert attacks
6.4 Safety Evaluation
- Benchmarks: RealToxicityPrompts, CrowS-Pairs, TruthfulQA
7. Evaluation Summary (Section 2.3 & 3.4)
- LLaMA 2-Chat 13B ≈ GPT-3.5 on many tasks
- Competitive across helpfulness, harmlessness, and instruction following
- Detailed performance across classification, reasoning, QA, code
8. Conclusion
- LLaMA 2 is a refinement, not a radical redesign
- Scales better, aligns better, and chats more reliably than LLaMA 1
- Released for open research and limited commercial use